Po co ochrona zasobów w procesorze?
Głównym przeznaczeniem mechanizmu ochrony zasobów zawartego w procesorze Intel386 jest ułatwienie wykrywania i identyfikacji błędów programowych, jak również odseparowanie aplikacji od systemu operacyjnego lub odseparowanie od siebie aplikacji różnych użytkowników pracujących na różnych poziomach uprzywilejowania.
Ochrony zasobów dotyczy pięciu aspektów bezpieczeństwa pracy procesora:
- sprawdzanie typu
- sprawdzanie limitu
- restrykcje odnośnie adresowania
- restrykcje odnośnie wykonywania kodu
- restrykcje odnośnie listy instrukcji
Mechanizm sprzętowej ochrony zasobów jest integralną częścią mechanizmu zarządzania pamięcią i dotyczy zarówno kroku translacji segmentowej jak i stronicowania.
Każdy dostęp do pamięci jest sprawdzany przez procesor w celu zweryfikowania czy spełnia on kryteria ochrony. Dzieje się to przed właściwym wykonaniem danej instrukcji, więc jakiekolwiek naruszenie zasad ochrony powoduje wywołanie wyjątku, uruchomienie odpowiedniej procedury obsługi, a następnie, jeśli jest to możliwe lub potrzebne, pozwala na powrót do tej instrukcji.
Pojęcie poziomów uprzywilejowania jest kluczowe dla większości aspektów ochrony zasobów. W stosunku do procedur jest to stopień w jakim można zaufać danej procedurze, że nie wykona ona żadnych operacji które mogą mieć negatywny wpływ na inne procedury. W stosunku do danych jest to stopień ochrony jakie powinny określone informacje posiadać przed ingerencją procedur o mniejszym stopniu zaufania.
Ochrona na poziomie segmentacji
W mechanizmie segmentacji uwzględnione zostały wszystkie z wcześniej wymienionych aspektów ochrony. Jednostką ochranianą jest tu cały sektor, a informacje dotyczące ochrony znajdują się w deskryptorze. Warunki dostępu są sprawdzane automatycznie przez procesor, kiedy selektor segmentu jest ładowany do rejestru segmentowego i podczas każdego dostępu do segmentu. Rejestry segmentowe przechowują parametry ochrony aktualnie adresowanego rejestru.
Parametry ochrony są ustawiane w deskryptorze przez system operacyjny w czasie tworzenia deskryptora. Zazwyczaj aplikacje użytkownika nie mają wpływu na te parametry.
Kiedy aplikacja ładuje selektor do rejestru segmentowego, procesor ładuje do części niewidocznej dla programisty nie tylko adres bazowy i limit segmentu, lecz także informacje na temat zabezpieczenia danego segmentu. Dzięki temu mechanizm ochrony, w obrębie tego segmentu, nie potrzebuje dodatkowego czasu.
Pola dotyczące ochrony zasobów znajdujące się w deskryptorze.
Pole typ
Pole typu w deskryptorze ma na celu informowanie procesora o rodzaju formatu deskryptora i sposobu w jaki jego zawartość ma być obsługiwana. Procesor poza typowymi deskryptorami używanymi przez aplikacje, posiada szereg typów deskryptorów stosowanych przez system operacyjny. Nie wszystkie z deskryptorów 'specjalnego przeznaczenia' określają segmenty pamięci - istnieją też deskryptory bramek (ang. gate).
Pole typu dla deskryptorów segmentów danych i kodu posiadają bity określające przeznaczenie danego segmentu:
 |
| Rys. Pole typu dla deskryptora segmentu danych |
 |
| Rys. Pole typu dla deskryptora segmentu kodu |
Znaczenie bitów pola typu deskryptorów danych i kodu :
- W - bit zapisu - określa czy istnieje możliwość zapisu do danego segmentu
- R - bit odczytu - określa czy istnieje możliwość odczytu z danego segmentu (np. dostęp do stałych zawartych w kodzie programu).
- A - bit dostępu
- C - bit zgodności poziomów (ang. conforming bit) - określa sposób ustawiania wartości CPL względem DPL; umożliwia wywoływanie procedur różnych poziomów z zachowaniem aktualnego CPL
- E - bit rozszerzalności segmentu (ang. expand-down bit) - określa sposób interpretacji wartości limitu segmentu; umożliwia stworzenie segmentów o zmiennej wielkość (np. rozszerzającego się stosu)
Sprawdzanie typów segmentów może być przydatne do wykrywania błędów - prób dostępu do segmentu w sposób nie zamierzony przez programistę. Procesor sprawdza parametry typu segmentu w przypadku:
- ładowania selektora do rejestru segmentowego
- do rejestru CS można załadować jedynie deskryptor określony jako deskryptor kodu;
- selektory segmentów wykonywalnych które nie są do odczytu nie mogą być załadowane jako selektory segmentów danych
- do rejestru SS mogą być załadowane jedynie selektory zapisywalnych segmentów
- kiedy instrukcja procesora odnosi się do rejestru segmentowego np.
- nie można zapisać do segmentu oznaczonego jako wykonywalny
- nie można zapisać do segmentu danych jeżeli nie jest ustawiony jako do zapisu
- nie można czytać segmentu wykonywalnego, dopóki nie będzie ustawiony jako do odczytu
| Kod | Typ segmentu | Kod | Typ segmentu | Kod | Typ segmentu |
| 0 | Zarezerwowane | 6 | Bramka przerwań 286 | B | Zajęty 386 TSS |
| 1 | Dostępny 286 TSS | 7 | Bramka pułapek 286 | C | Bramka wywołań sys.386 |
| 3 | Zajęty 286 TSS | 8 | Zarezerwowane | D | Zarezerwowane |
| 4 | Bramka wywołań sys. | 9 | Dostępny 386 TSS | E | Bramka przerwań 386 |
| 5 | Bramka zadania | A | Zarezerwowane | F | Bramka pułapek 386 |
Pole limitu
Pole limitu w deskryptorze segmentu jest używane przez procesor do ochrony programów przed adresacją poza określonymi obszarami pamięci. Interpretacja tego bitu zależy od ustawienia bitu ziarnistości G, oraz dla segmentu danych od bitu rozszerzalności segmentu E i bitu wielkości B (bit w deskryptorze segmentu danych)
Kiedy wartość bitu G wynosi 0, pole limitu jest interpretowane tak jak przedstawia się to w deskryptorze - segment może mieć wielkość od 0 do 0xFFFFF (do 1MB). Kiedy wartość bitu G wynosi 1 procesor rozszerza pole limitu o 12 najmniej znaczących bitów. W tym przypadku wielkość segmentu może wynosić od 0xFFF do 0xFFFFFFFF (od 4KB do 4GB).
Dla wszystkich typów segmentów, z wyjątkiem segmentów z ustawioną opcją rozszerzania, wartość limitu jest zawsze mniejsza o 1 bajt od wielkości segmentu. Procesor wywołuje wyjątki ochrony kiedy:
- nastąpiła próba dostępu do zmiennej o wielkości jednego bajtu i adresie > limitu
- nastąpiła próba dostępu do zmiennej o wielkości jednego słowa i adresie>=limitowi
- nastąpiła próba dostępu do zmiennej o wielkości podwójnego słowa i adresie >= (limit - 2)
Dla segmentów z ustawioną opcją rozszerzania, pole limitu ma podobne zadanie, lecz jest interpretowane nieco inaczej - obszar właściwego adresu leży w zakresie (limit + 1, limit + 64 KB) lub też przy G ustawionym na jeden, w zakresie (limit + 1, limit + 4GB - 1).
Pole limitu dla tablicy deskryptora, zawarte w rejestrze GDTR, uniemożliwia wybranie deskryptora z poza tablicy deskryptorów. Ponieważ każdy z deskryptorów ma wielkość 8 bajtów, wielkość tego limitu wynosi N*8 - 1 dla tablicy zawierającej N deskryptorów.
Pole DPL, RPL, CPL - poziomy uprzywilejowania
W procesorze Intel386 występują cztery poziomy uprzywilejowania. Wartość zero jest interpretowana jako poziom najbardziej uprzywilejowany, natomiast wartość trzy oznacza poziom najmniej uprzywilejowany. Rozmieszczenie poszczególnych pól:
- deskryptory zawierają pole poziomu uprzywilejowania deskryptora (DPL)
- selektory zawierają pole żądanego poziomu uprzywilejowania (RPL)
- wewnętrzny rejestr procesora zawiera wartość obecnego poziomu uprzywilejowania (CPL).
Zazwyczaj CPL jest równe DPL segmentu, który obecnie jest wykonywany. Wartość CPL zmienia się podczas przeniesienia wykonywania programu do segmentu z innym DPL niż obecny.
Procesor automatycznie ocenia prawa dostępu do segmentu poprzez porównanie obecnego poziomu uprzywilejowania do żądanego poziomu uprzywilejowania lub poziomu uprzywilejowania jaki ma deskryptor interesującego nas segmentu.
Nie jest wymagane używanie wszystkich czterech poziomów uprzywilejowania. Zazwyczaj stosowane jest zabezpieczenie jedno lub dwu poziomowe. W przypadku systemów z zabezpieczeniem jednopoziomowym procesor powinien używać najwyższego poziomu uprzywilejowania (wartość 0), a dla systemów dwupoziomowych powinien być stosowany najwyższy i najniższy poziom uprzywilejowania (odpowiednio wartość 0 i 3).
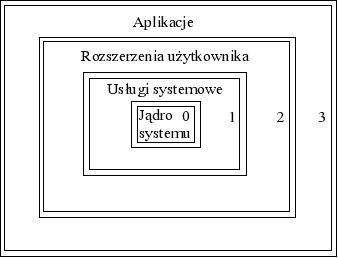 |
| Rys. Przykład wykorzystania poziomów uprzywilejowania |
Instrukcje mogą załadować deskryptory segmentu danych (i go używać) jeżeli DPL segmentów przeznaczenia jest większy lub równy (co do wartości numerycznej) wartości pól CPL i RPL. Innymi słowami - dostęp jest uprawniony, gdy żądamy danych z niższego lub takiego samego poziomu uprzywilejowania jaki mamy obecnie.
W procesorze Intel386 zmiany kontroli są dokonywane przez instrukcję JMP, CALL, RET, INT, oraz IRET jak również przez mechanizm obsługi przerwań i wyjątków. Ponieważ zmiana poziomu uprzywilejowania najczęściej następuje wraz ze zmianą segmentu, dotyczy to głownie instrukcję z przedrostkiem FAR. Procesor zezwala na zmianę kontroli nad programem kiedy:
- wartość DPL jest równa CPL
- bit zgodności poziomów w deskryptorze segmentu przeznaczenia jest ustawiony, a wartość DPL jest mniejsza lub równa CPL. W tym przypadku, po przeniesieniu kontroli do żądanej procedury, wartość CPL się nie zmienia (CPL <> DPL)
Większość segmentów kodu nie są oznaczone bitem zgodności poziomów w deskryptorze, więc najczęściej przekazywanie kontroli odbywa się między segmentami kodu z tym samym poziomem uprzywilejowania. Jednakże istnieje potrzeba przeniesienia kontroli pomiędzy poszczególnymi poziomami uprzywilejowania (np. wywołanie procedur z bibliotek, wywołania systemowe itp.). Wykonuje się to poprzez tak zwane 'bramki' , zawarte zarówno w mechanizmie wyjątków, jak i segmentacji. Bramki wywołania (ang. call gate) zawarte w tablicy deskryptorów są to specjalnego rodzaju deskryptory, które wskazują na adres wejścia do obsługi procedury, ustawiają odpowiedni poziom uprzywilejowania. 'Przejścia przez bramkę' dokonuje się wywołując ją instrukcją CALL.
W celu zachowania integralności systemu, każdy z poziomów uprzywilejowania posiada swój własny stos programowy. Procesor orientuje się gdzie który stos jest umieszczony, dzięki wpisom w segmencie stanu zadania TSS. Segment ten jest tworzony przez system operacyjny podczas tworzenia zadania - zazwyczaj każde zadanie posiada swój własny TSS. W czasie zmiany poziomu uprzywilejowania wskaźniki stosu są pobierane z pól segmentu zadania zgodnie z wartością DPL segmentu przeznaczenia, odpowiednio pary - do - . Wartość DPL segmentu danych w którym został umieszczony stos musi być zgodny z nową wartością CPL, w przeciwnym przypadku procesor wygeneruje wyjątek. Wielkość stosu musi być odpowiednia, aby pomieścić na nim odłożone stare wartości SS:ESP, adres powrotu i ewentualne parametry czy zmienne lokalne.
Instrukcje zarezerwowane dla systemu operacyjnego
Instrukcje, których użycie może spowodować naruszenie ochrony systemu, lub które mogły by mieć wpływ na wydajność, mogą być wykonywane jedynie przez 'zaufane' procedury. Procesor Intel386 posiada dwa rodzaje takich instrukcji:
- instrukcje uprzywilejowane - używane do kontroli nad systemem
- instrukcje 'zależne' (ang. Sensitive instructions) - używane do operacji wejścia/wyjścia i podobnymi
Instrukcje mające wpływ na systemowe struktury danych mogą być wykonane jedynie wtedy, gdy obecny poziom uprzywilejowania wynosi zero. Jeśli procesor zauważy próbę wykonania takiej instrukcji w innym poziomie uprzywilejowania zasygnalizuje to wyjątkiem naruszenia ochrony.
| Mnemonik | Opis instrukcji |
| CLTS | Czyszczenie flagi przełączenia zadania |
| HLT | Zatrzymanie procesora |
| LGDT | Załadowanie globalnej tablicy deskryptorów do rejestru GDT |
| LIDT | Załadowanie tablicy deskryptorów przerwań do rejestru IDT |
| LLDT | Załadowanie lokalnej tablicy deskryptorów do rejestru LDT |
| LMSW | Załadowanie słowa stanu procesora |
| LTR | Załadowanie rejestru zadania TR |
| MOV z/do CRn | Operacje przesyłu danych na rejestrach kontrolnych |
| MOV z/do DRn | Operacje przesyłu danych na rejestrach mechanizmu debuggera |
| MOV z/do TRn | Operacje przesyłu danych na rejestrach testowych |
| POPF (-> IOPL) | POPF (-> IOPL) |
Instrukcje służące do operacji wejścia wyjścia nazwane są zależnymi, gdyż ich wykonanie zależy od wartość flagi IOPL. Aby wykonać taką instrukcje procedura musi się wykonywać na poziomie uprzywilejowania przynajmniej takim, na jaki wskazuje IOPL (CPL<=IOPL). Próba dostępu nie spełniająca tego warunku zostanie zablokowana, następnie procesor wywoła wyjątek naruszenia ochrony.
Innym sposobem umożliwienia dostępu do instrukcji wejścia/wyjścia procedurom poziomom niższym niż systemowy jest zastosowanie bitmapy dostępności portów wejścia/wyjścia (ang. I/O permission bit map). Bitmapa ta umieszczona jest w segmencie TSS zadania. Każdy bit w tej strukturze oznacza konkretny port - wyzerowanie jego wartości powoduje wyłączenie generowanie wyjątku naruszenia ochrony i zezwolenie na korzystanie z danego portu.
Procesor sprawdza bitmapę dostępności portów, jeżeli nie ma spełnionego warunku CPLCPL<=IOPL . Wyjątkiem jest tu tryb wirtualny procesora, w którym to dostęp do portów zależy tylko od bitmapy.
Nie ma potrzeby ustawiania wartości bitmapy dla każdego portu - bity nie ustawione będą traktowane tak jakby miały wartość 1 - wyłączony port.
Ochrona na poziomie stronicowania
W mechanizmie stronicowania występują dwa rodzaje ochrony danych: ochrona zasobów przed niepowołanym dostępem, oraz sprawdzanie czy operacja wykonywana na stronie danej stronie jest dozwolona.
W celu ochrony zasobów przed niepowołanym dostępem mechanizm stronicowania używa bitu U/S wpisu strony. Strona może mieć dwa poziomy uprzywilejowania:
- poziom administratora (U/S = 0) - dla oprogramowania systemowego i związanymi z nim danymi
- poziom użytkownika (U/S = 1) - dla kodu i danych aplikacji
Bieżący poziom uprzywilejowania zależy od wartości CPL. Jeżeli CPL jest mniejsze od trzech, procesor pracuje na poziomie administratora, w przeciwnym przypadku procesor pracuje na poziomie użytkownika.
W trybie administratora wszystkie strony są adresowalne, natomiast w trybie użytkownika dostępne są tylko te strony, które należą do tego użytkownika.
W celu zabezpieczenia przed wykonaniem nieodpowiedniej operacji pamięciowej na danej stronie mechanizm stronicowania używa bitu R/W wpisu strony. Są zdefiniowane dwa stany:
Kiedy procesor pracuje w trybie administratora wszystkie strony mają charakter odczyt - zapis/odczyt, natomiast jeśli procesor pracuje w trybie użytkownika, tylko strony będące własnością użytkownika są albo do zapisu/odczytu lub tylko odczytu.